Photo & Movies
視覚による動作理解に基づく人とロボットの協調作業
This research has been studied on under supervision of
Prof. Ikeuchi at his Lab in Univ. Tokyo.
[1999年度]
-
東大・池内研
はHumanoid型の新ロボットを開発しました.
以下のmovieは,11月20日に京都で開催されたCDV99でのデモです.
[1998年度]
-
ロボットは,1つの作業モデルに基づいて,人間の動作に応じて適切な補助動作を選んだ.
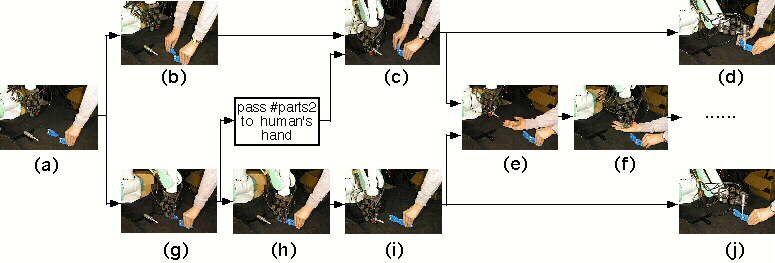
実行された協調作業のパターンは,以下の6通りである.
- (Movies)
(a) -> (b) -> (c) -> (d),(945Kbytes)
(a) -> (b) -> (c) -> (e) -> (f),(492Kbytes)
(a) -> (g) -> (c) -> (d),(1,163Kbytes)
(a) -> (g) -> (c) -> (e) -> (f),(739Kbytes)
(a) -> (g) -> (h) -> (i) -> (e) -> (f),
(a) -> (g) -> (h) -> (i) -> (j).(1,199Kbytes)
- それぞれのシーンは次の動作を表している.
(a)人が#parts1を把持した.
(b)人が#parts2を把持した.
(c)人が#parts2を#parts1に組み付けている間にロボットハンドが#driverを把持した.
(d)ロボットハンドが#driverを#parts1.f(3)に組み付けた.
(e)人が受け取り動作を行い,ロボットに#driverを渡すように要求した.
(f)ロボットが人に#driverを手渡した.
(g)ロボットハンドが#parts2を把持した.
(h)ロボットハンドが#parts2を#parts1に組み付けた.
(i)ロボットハンドが#driverを把持した.
(j)ロボットハンドが#driverを#parts1.f(3)に組み付けた.
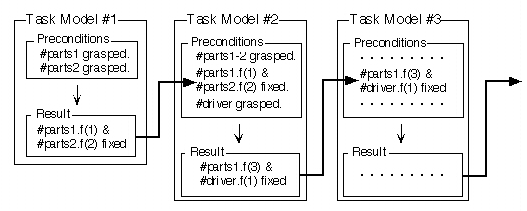
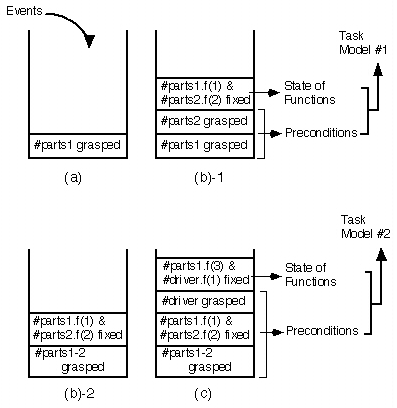
作業モデルは、
人のデモ (movie:993Kbytes)を
事象スタック機構を用いて
解析することにより、生成された。
[1996年度]



-
人の把持するオモチャパーツを視覚により認識し,
ロボットハンドが適切な相手パーツを組み付け位置まで持っていく.
- ビデオ



-
人が組み付けたオモチャパーツを視覚により認識し,
ロボットハンドがドライバを掴みネジ穴まで持っていく.
- ビデオ
 研究の経過・概要
研究の経過・概要
既発表論文,予稿集原稿
{kind=link}
{kind=link}
{kind=link}